初识大模型 0 - 预训练
初识大模型 0 - 预训练
Step 1. 从互联网下载数据
从网络上下载的数据需要经过第一步粗加工,比如如果是网站,需要把冗余的标签删掉,留下可读的文本部分;如果是 PDF 或者其他文本格式,都需要提取出纯文本。
然后是剔除敏感数据、非法数据、个人信息等。
通常我们可以可以在 hugging face 上找到社区里处理过的数据集。
Step 2. Tokenization
UTF-8 编码
我们知道,计算机只能处理二进制数据,而人类用于传输信息的数据有文字、符号、表情等抽象字符,而编码的存在就是为这些抽象字符分配唯一 ID(码点),并将这些 ID 转换为计算机能够识别的二进制表达。
比如“hello”,的 UTF-8 码点为 \u0068\u0065\u006c\u006c\u006f,二进制表示 01101000 01100101 01101100 01101100 01101111。
那是否我们在做预训练时,只要把文本转为二进制,然后对这些二进制序列建立神经网络就好了呢?
BPE/字节对编码
用于大模型训练的数据集通常是非常大的,比如比较热门的网络爬虫数据集 FineWeb 就有 51.3TB。
为了提高模型训练的和推理的效率,我们需要一种高效且可逆的编码算法压缩文本,并要求编解码操作是幂等的。
字节对编码(BPE)是常用的子词切分算法,目前常见的模型基本都用 BPE 进行文本压缩,其工作原理为:将文本拆解为多个单一的字符,为每个字符提供唯一的 id 建立词汇表。然后不断合并高频的连续字符,再给这些连续字符提供 id,直到这个词汇表达到我们设定的大小。
示例: 对"你好,我的名字是御正,我的工作是前端开发"进行 BPE。
1. 设置词汇表
| id | byte |
|---|---|
| 1 | 你 |
| 2 | 好 |
| 3 | , |
| 4 | 我 |
| 5 | 的 |
| 6 | 名 |
| 7 | 字 |
| 8 | 是 |
| 9 | 御 |
| 10 | 正 |
| 11 | 工 |
| 12 | 作 |
| 13 | 前 |
| 14 | 端 |
| 15 | 开 |
| 16 | 发 |
当前最高频的字符组合为[',', '我']
| ... | ... |
|---|---|
| 17 | ,我 |
当前最高频的字符组合为['我', '的']
| ... | ... |
|---|---|
| 18 | 我的 |
当前最高频的字符组合为[',我', '的']
| ... | ... |
|---|---|
| 19 | ,我的 |
2. 编码
你好,我的名字是御正,我的工作是前端开发
1,2,19,6,7,8,9,10,19,11,12,13,14,15,16
Tokenizer
目前常见的模型在预训练和推理时都需要这样一个词汇表来切分文本,而使用的词汇表不同,就会带来专业方向、语言、效率上的区别。
比如 OpenAI 的 tiktoken 基于字节级 BPE 预训练的词汇表,以 UTF-8 字节(0x00~0xFF)为初始单元,覆盖所有 Unicode 字符、控制字符(如 \n)甚至二进制数据(如图像的 0xFF 字节)。我们可以通过 https://tiktokenizer.vercel.app 可视化观测 tiktoken 时如何计算文本 token 的。
DeepSeek 的 deepseek-tokenizer 针对中文和代码场景进行了优化,采用字级分词 + BPE 混合方案。
from deepseek_tokenizer import ds_token
import tiktoken
import sentencepiece as spm
text = "Hello!我是御正"
print("deepseek:" + str(ds_token.encode(text)))
print("tiktoken o200k_base:" + str(tiktoken.get_encoding("o200k_base").encode(text)))
print("tiktoken cl100k_base:" + str(tiktoken.get_encoding("cl100k_base").encode(text)))
# deepseek:[19923, 3, 10805, 12476, 1287]
# tiktoken o200k_base:[13225, 0, 176389, 107436, 10170]
# tiktoken cl100k_base:[9906, 0, 37046, 21043, 17599, 94, 37656]
Google 的 SentencePiece 除了 BPE,还额外提供了 unigram 语言模型 优化分词准确性。
简单来说是统计用于训练的语料库里每个单词出现的概率,然后计算不同的切分方式的概率,选择概率最高的切分方式作为最终结果。
总结
词汇表的构成:
- 常见单词/子词(如 “人工智能” 作为一个 Token)
- 特殊符号(如 <|begin_of_text|>、标点)
- 低频词的拆分组合(如通过字节对编码 BPE 生成的子词)
- 随着多模态大模型的发展,后续词汇表也会逐步引入图像、音频的特征 token
3. 训练神经网络
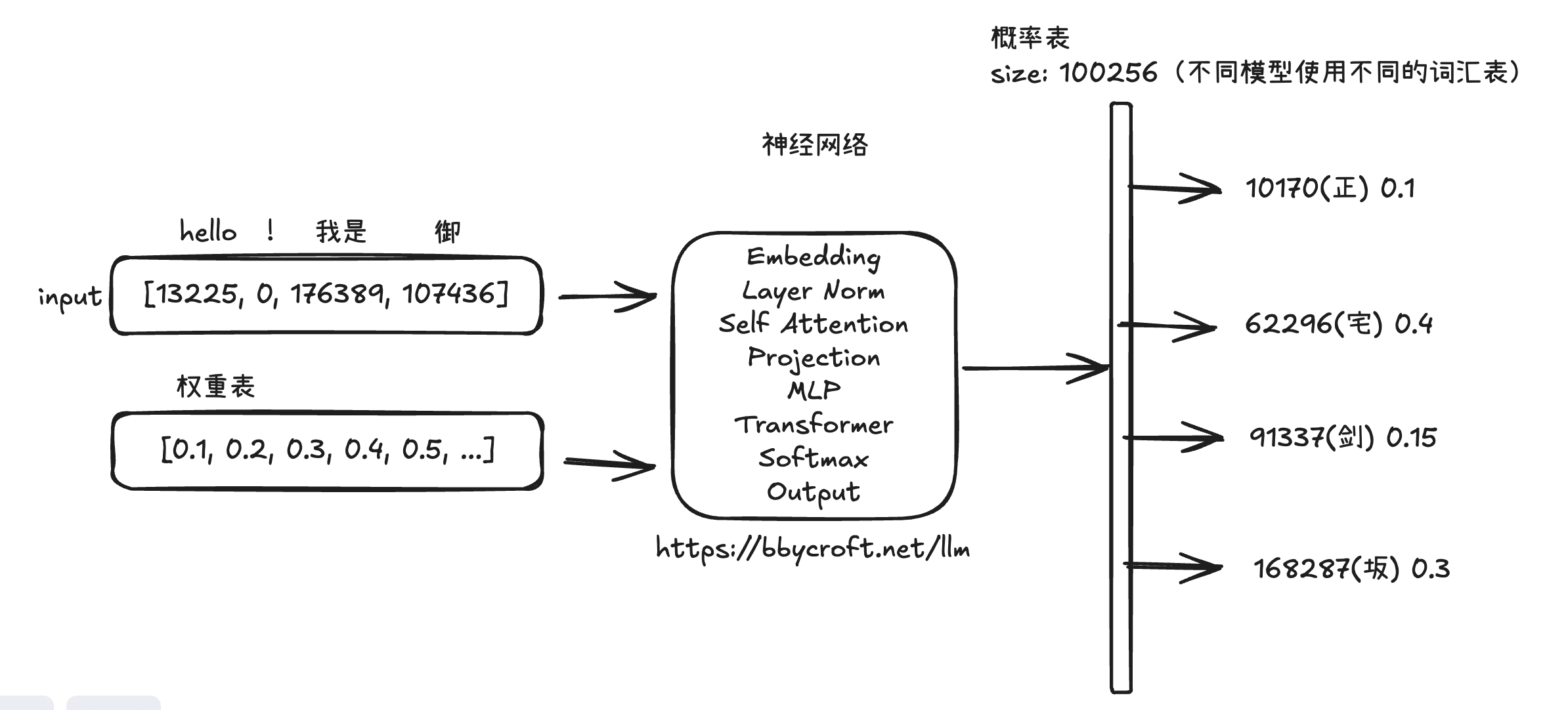
图示为一个简单的 LLM 模型推理过程,input 的内容为输入字符经过 tokenization 的 token 序列。
权重表就是神经网络参数,目前的参数大小有几十到几千亿不等,我们可以根据运行设备的规格选择不同参数大小的模型。
通常用于推理的模型,都需要预先训练好效果相对最佳的参数集,具体过程如下:
- 模型初始化:初始化神经网络参数(权重),这些参数通常是随机值。
- 前向传播:将数据输入模型,经过嵌入(Embedding)、自注意力(Self - Attention)、多层感知机(MLP)等组件处理,生成预测输出(如词的概率分布)。
- 计算损失:通过损失函数(如交叉熵损失)比较预测输出与真实标签的差异,衡量模型当前误差。
- 反向传播与优化:利用反向传播算法计算损失对各层权重的梯度,借助优化器更新权重,使损失减小。
- 迭代训练:重复前向传播、计算损失、反向传播过程,历经多轮训练,逐渐调整权重,让损失值降到最低。
- 最终,训练完成后,模型各层的参数构成权重表,存储了模型学习到的语言知识与模式,用于推理时生成合理输出。
https://bbycroft.net/llm 这个网站可视化的展示了 LLM 是如何处理输入数据的。